| Автор |
Сообщение |
|
|
| |
Заголовок сообщения: |
|
 |
|
Цитата: вот такой текст:
WingLion писал(а):
В форте каждое высокоуровневое слово требует исполнения NEXT, если и само NEXT будет высокоуровневым, то задержка окажется существенной.
за "какую-нибудь оценку" сойдет? Угу, как это я пропустил ... Цитата: голый IF выполняется быстрее чем префиксный IF. Вот только для "голого" вершину стека придется специально "готовить" (варить, солить или жарить), а это уже будет медленнее, чем IF с прямым указанием условия для перехода
ну да [quote]вот такой текст:
WingLion писал(а):
В форте каждое высокоуровневое слово требует исполнения NEXT, если и само NEXT будет высокоуровневым, то задержка окажется существенной.
за "какую-нибудь оценку" сойдет?[/quote]
Угу, как это я пропустил ...
[quote]голый IF выполняется быстрее чем префиксный IF. Вот только для "голого" вершину стека придется специально "готовить" (варить, солить или жарить), а это уже будет медленнее, чем IF с прямым указанием условия для перехода [/quote]
ну да
|
|
|
 |
Добавлено: Сб дек 05, 2009 17:45 |
|
|
 |
|
|
| |
Заголовок сообщения: |
|
|
|
вопрос писал(а): Какая-нибудь оценка прироста производительности вследствие такой оптимизации как NEXT и вызов за 1 такт производилась? вот такой текст: WingLion писал(а): В форте каждое высокоуровневое слово требует исполнения NEXT, если и само NEXT будет высокоуровневым, то задержка окажется существенной.
: NEXT R> DUP 1+ >R EXECUTE ; - грубо - 5 тактов, а в железе NEXT исполняется за 2 такта,
Если в каждом высокоуровневом слове в среднем 5-7 слов, то получается 15-25 тактов выигрыша на каждое слово. Мелочь, конечно, но душу греет. Wink
Кроме того, железный NEXT позволяет делать очень коротенькие слова вплоть до 1 CELL на слово, т.е. в одном слове три команды + NEXT, а в потоке адресной интерпретации только ссылка на адрес, где это слово с командами лежит. Т.е. хороший выигрыш не только по тактам, но и по занимаемому объему, что довольно важно для ограниченной внутренней памяти ПЛИС. за "какую-нибудь оценку" сойдет? вопрос писал(а): это, я понимаю, тоже несколько быстрее, чем просто IF
голый IF выполняется быстрее чем префиксный IF. Вот только для "голого" вершину стека придется специально "готовить" (варить, солить или жарить), а это уже будет медленнее, чем IF с прямым указанием условия для перехода [quote="вопрос"]Какая-нибудь оценка прироста производительности вследствие такой оптимизации как NEXT и вызов за 1 такт производилась? [/quote]
вот такой текст:
[quote="WingLion"]В форте каждое высокоуровневое слово требует исполнения NEXT, если и само NEXT будет высокоуровневым, то задержка окажется существенной.
: NEXT R> DUP 1+ >R EXECUTE ; - грубо - 5 тактов, а в железе NEXT исполняется за 2 такта,
Если в каждом высокоуровневом слове в среднем 5-7 слов, то получается 15-25 тактов выигрыша на каждое слово. Мелочь, конечно, но душу греет. Wink
Кроме того, железный NEXT позволяет делать очень коротенькие слова вплоть до 1 CELL на слово, т.е. в одном слове три команды + NEXT, а в потоке адресной интерпретации только ссылка на адрес, где это слово с командами лежит. Т.е. хороший выигрыш не только по тактам, но и по занимаемому объему, что довольно важно для ограниченной внутренней памяти ПЛИС. [/quote]
за "какую-нибудь оценку" сойдет?
[quote="вопрос"]это, я понимаю, тоже несколько быстрее, чем просто IF[/quote]
голый IF выполняется быстрее чем префиксный IF. Вот только для "голого" вершину стека придется специально "готовить" (варить, солить или жарить), а это уже будет медленнее, чем IF с прямым указанием условия для перехода
|
|
|
|
Добавлено: Сб дек 05, 2009 17:27 |
|
|
|
|
|
| |
Заголовок сообщения: |
|
|
|
Цитата: Это пока проект. Увлекательно ... Большая "куча" возможностей. Какая-нибудь оценка прироста производительности вследствие такой оптимизации как NEXT и вызов за 1 такт производилась?
0. - IF Z
1. - IF NZ
2. - IF больше 0
3. - IF меньше 0
это, я понимаю, тоже несколько быстрее, чем просто IF [quote]Это пока проект. [/quote] Увлекательно ... Большая "куча" возможностей. Какая-нибудь оценка прироста производительности вследствие такой оптимизации как [b]NEXT и вызов за 1 такт[/b] производилась?
0. - IF Z
1. - IF NZ
2. - IF больше 0
3. - IF меньше 0
это, я понимаю, тоже несколько быстрее, чем просто IF
|
|
|
|
Добавлено: Сб дек 05, 2009 16:45 |
|
|
|
|
|
| |
Заголовок сообщения: |
|
|
|
вопрос писал(а): а какие 16 условий Question
три бита модификатора для IF (все для TOP) - коды (ориентировочно):
0. - IF Z
1. - IF NZ
2. - IF больше 0
3. - IF меньше 0
4. - IF не больше 0 (меньше или равно)
5. - IF не меньше 0 (больше или равно)
6. - IF старший бит TOP = 1
7. - IF младший бит TOP = 1
Четвертый бит модификатора IF - использовать следующий ниббл из потока команд, как смещение для условного перехода (от -7 до +7).
код смещения 0 - означает условное исполнение следующего ниббла (получатся условный RET, условный NEXT и т.п.)
п.с. Это пока проект. Возможно все будет по другому. [quote="вопрос"]а какие 16 условий Question[/quote]
три бита модификатора для IF (все для TOP) - коды (ориентировочно):
0. - IF Z
1. - IF NZ
2. - IF больше 0
3. - IF меньше 0
4. - IF не больше 0 (меньше или равно)
5. - IF не меньше 0 (больше или равно)
6. - IF старший бит TOP = 1
7. - IF младший бит TOP = 1
Четвертый бит модификатора IF - использовать следующий ниббл из потока команд, как смещение для условного перехода (от -7 до +7).
код смещения 0 - означает условное исполнение следующего ниббла (получатся условный RET, условный NEXT и т.п.)
п.с. Это пока проект. Возможно все будет по другому.
|
|
|
|
Добавлено: Сб дек 05, 2009 14:13 |
|
|
|
|
|
| |
Заголовок сообщения: |
|
|
|
Цитата: IF префиксной. Тогда можно сделать до 16 условий. Или 8 условий плюс признак короткого ветвления с переходом по 16-битному смещению. а какие 16 условий  [quote]IF префиксной. Тогда можно сделать до 16 условий. Или 8 условий плюс признак короткого ветвления с переходом по 16-битному смещению.[/quote] а какие 16 условий :?:
|
|
|
|
Добавлено: Сб дек 05, 2009 13:10 |
|
|
|
|
|
| |
Заголовок сообщения: |
|
|
|
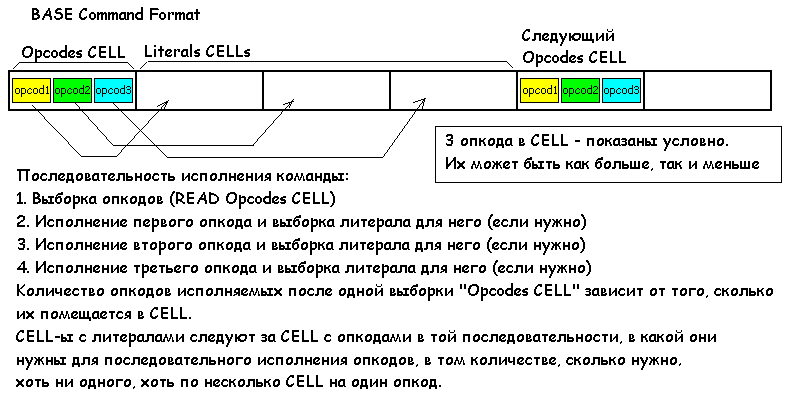
in4 писал(а): А можно даже больше таких команд, используя как адрес все оставшиеся биты CELL-а! Пока еще думаю об этом. Экономия будет только для подпрограммного кода, а его преимущества при наличии железного адресного интерпретатора кажутся сомнительными. in4 писал(а): Но, может, и другие операции со стеком возврата добавить - для циклов, для косвеной адресации через верхушку RS... А еще один-два индексных регистра с автоинкрементом, воможность байтовой адресации, литералы к команде... Сильно усложнять процессор тоже не хочется. Для байтового доступа пока сделана только команда BSWAP - перестановка байтов в слове, понадобится больше - буду думать. С индексными регистрами тоже могут возникнуть вопросы - а где коды команд для них брать? in4 писал(а): А не от 2х четверок? Wink Или так нельзя, тогда почему? (Даже при CELL=8бит данные могут быть и 2х-байтные, 2 CELL на данное. Еще можно сделать 2 вида литерала, один из которых берет байт но с расширением знака - экономия Wink ) Восьмибитный вариант процессора по какой-то причине у меня не заработал сразу в общей схеме (через установку параметра в исходнике - WIDTH=8 ). И я еще не разбирался почему. Но, думаю такой вариант процессора имеет право на существование. Для каких-нибудь мелких контроллеров. И по объему, он наверняка уместится в очень маленькую ПЛИС-ку. in4 писал(а): Просто на рисунке сделано по-другому и может вызвать запинки и ненужные вопросы. Хотя это м.б. и тест на понимание, типа входного контроля читающего, как посмотреть... Рисунок надо бы просто переделать. А то он делался раньше, еще для другого процессора (о нем можно уже забыть). in4 писал(а): Имелось ввиду использовать этот термин в описании проца. Wink
(Сейчас не используется и ячейки называются длинными фразами "группа команд" (=CELL), "группами, упакованными в машинное слово"(=CELL-ами), "среди загруженных команд"(=в CELL) и т.п.) Описание буду править полностью, когда доделаю целевой компилятор и на нем (процессоре) заработает полноценный форт. Тогда можно будет внести исправления, что появятся в процессе отладки. Да и описание самой встроенной системы с форт-процессором добавить. in4 писал(а): Кстати, не хочешь бОльше условий добавить?
Проверку на отрицательное, по переносу (если флаг переноса делать не хочешь, тогда почему?) Как без переноса делать D+ ?
Думаю о том, чтобы сделать команду IF префиксной. Тогда можно сделать до 16 условий. Или 8 условий плюс признак короткого ветвления с переходом по 16-битному смещению.
На префиксность еще и LIT просится для организации коротких и длинных литералов. [quote="in4"]А можно даже больше таких команд, используя как адрес все оставшиеся биты CELL-а![/quote]
Пока еще думаю об этом. Экономия будет только для подпрограммного кода, а его преимущества при наличии железного адресного интерпретатора кажутся сомнительными.
[quote="in4"]Но, может, и другие операции со стеком возврата добавить - для циклов, для косвеной адресации через верхушку RS... А еще один-два индексных регистра с автоинкрементом, воможность байтовой адресации, литералы к команде...[/quote]
Сильно усложнять процессор тоже не хочется. Для байтового доступа пока сделана только команда BSWAP - перестановка байтов в слове, понадобится больше - буду думать.
С индексными регистрами тоже могут возникнуть вопросы - а где коды команд для них брать?
[quote="in4"]А не от 2х четверок? Wink Или так нельзя, тогда почему? (Даже при CELL=8бит данные могут быть и 2х-байтные, 2 CELL на данное. Еще можно сделать 2 вида литерала, один из которых берет байт но с расширением знака - экономия Wink ) [/quote]
Восьмибитный вариант процессора по какой-то причине у меня не заработал сразу в общей схеме (через установку параметра в исходнике - WIDTH=8 ). И я еще не разбирался почему.
Но, думаю такой вариант процессора имеет право на существование. Для каких-нибудь мелких контроллеров. И по объему, он наверняка уместится в очень маленькую ПЛИС-ку.
[quote="in4"]Просто на рисунке сделано по-другому и может вызвать запинки и ненужные вопросы. Хотя это м.б. и тест на понимание, типа входного контроля читающего, как посмотреть... [/quote]
Рисунок надо бы просто переделать. А то он делался раньше, еще для другого процессора (о нем можно уже забыть).
[quote="in4"]Имелось ввиду использовать этот термин в описании проца. Wink
(Сейчас не используется и ячейки называются длинными фразами "группа команд" (=CELL), "группами, упакованными в машинное слово"(=CELL-ами), "среди загруженных команд"(=в CELL) и т.п.) [/quote]
Описание буду править полностью, когда доделаю целевой компилятор и на нем (процессоре) заработает полноценный форт.
Тогда можно будет внести исправления, что появятся в процессе отладки. Да и описание самой встроенной системы с форт-процессором добавить.
[quote="in4"]Кстати, не хочешь бОльше условий добавить?
Проверку на отрицательное, по переносу (если флаг переноса делать не хочешь, тогда почему?) Как без переноса делать D+ ?[/quote]
Думаю о том, чтобы сделать команду IF префиксной. Тогда можно сделать до 16 условий. Или 8 условий плюс признак короткого ветвления с переходом по 16-битному смещению.
На префиксность еще и LIT просится для организации коротких и длинных литералов.
|
|
|
|
Добавлено: Сб дек 05, 2009 12:07 |
|
|
|
|
|
| |
Заголовок сообщения: |
|
|
|
WingLion писал(а): А я подумываю о том, чтобы использовать оставшееся пространство для коротких вызовов, например, сделать так, что если за командой CALL следует не нулевой ниббл, то исполняется одна из 15 подпрограмм с фиксированным адресом. Подобно INT #nn в Z80. А можно даже больше таких команд, используя как адрес все оставшиеся биты CELL-а!  WingLion писал(а): Хм... вот, прямо тут сразу и идейка появилась для новой команды! ) R+@ которая выполняет R> DUP 1+ >R @ для вытаскивания такого операнда (за 2 такта).
Думаю, такое слово будет полезно. В процессоре оно будет исполняться очень быстро, и в железе оно не много места потребует, потому что R> DUP 1+>R фактически уже делается для NEXT. Хорошо бы... Но, может, и другие операции со стеком возврата добавить - для циклов, для косвеной адресации через верхушку RS... А еще один-два индексных регистра с автоинкрементом, воможность байтовой адресации, литералы к команде... WingLion писал(а): Кроме того, железный NEXT позволяет делать очень коротенькие слова вплоть до 1 CELL на слово, т.е. в одном слове три команды + NEXT, а в потоке адресной интерпретации только ссылка на адрес, где это слово с командами лежит. После этого^ в сочетании с др. объяснениями - проникся... WingLion писал(а): этот рисунок сильно упрощен. Надо подразумевать, что в CELL может быть от 3 до 16 четверок в CELL А не от 2х четверок? Или так нельзя, тогда почему? (Даже при CELL=8бит данные могут быть и 2х-байтные, 2 CELL на данное. Еще можно сделать 2 вида литерала, один из которых берет байт но с расширением знака - экономия ) WingLion писал(а): При исполнении команд, сначала исполняется самая правая (младшая) четверка бит, сдвиг в регистре команды происходит на 4 бита 'вправо'. Просто на рисунке сделано по-другому и может вызвать запинки и ненужные вопросы. Хотя это м.б. и тест на понимание, типа входного контроля читающего, как посмотреть... WingLion писал(а): in4 писал(а): Может, ввести термин CELL для обозначения адресуемой единицы памяти (и одновременно группы команд в ней)? Ну странновато звучит предложение ввести термин, который уже давно как бы стандартен Имелось ввиду использовать этот термин в описании проца.
(Сейчас не используется и ячейки называются длинными фразами "группа команд" (=CELL), "группами, упакованными в машинное слово"(=CELL-ами), "среди загруженных команд"(=в CELL) и т.п.)
Кстати, не хочешь бОльше условий добавить?
Проверку на отрицательное, по переносу (если флаг переноса делать не хочешь, тогда почему?) Как без переноса делать D+ ? [quote="WingLion"]А я подумываю о том, чтобы использовать оставшееся пространство для коротких вызовов, например, сделать так, что если за командой CALL следует не нулевой ниббл, то исполняется одна из 15 подпрограмм с фиксированным адресом. Подобно INT #nn в Z80.[/quote]А можно даже больше таких команд, используя как адрес все оставшиеся биты CELL-а! ;)
[quote="WingLion"]Хм... вот, прямо тут сразу и идейка появилась для новой команды! ) R+@ которая выполняет R> DUP 1+ >R @ для вытаскивания такого операнда (за 2 такта).
Думаю, такое слово будет полезно. В процессоре оно будет исполняться очень быстро, и в железе оно не много места потребует, потому что R> DUP 1+>R фактически уже делается для NEXT.[/quote]Хорошо бы... ;) Но, может, и другие операции со стеком возврата добавить - для циклов, для косвеной адресации через верхушку RS... А еще один-два индексных регистра с автоинкрементом, воможность байтовой адресации, литералы к команде... ;)
[quote="WingLion"]Кроме того, железный NEXT позволяет делать очень коротенькие слова вплоть до 1 CELL на слово, т.е. в одном слове три команды + NEXT, а в потоке адресной интерпретации только ссылка на адрес, где это слово с командами лежит.[/quote]После этого^ в сочетании с др. объяснениями - проникся... ;)
[quote="WingLion"]этот рисунок сильно упрощен. Надо подразумевать, что в CELL может быть от 3 до 16 четверок в CELL[/quote]А не от 2х четверок? ;) Или так нельзя, тогда почему? (Даже при CELL=8бит данные могут быть и 2х-байтные, 2 CELL на данное. Еще можно сделать 2 вида литерала, один из которых берет байт но с расширением знака - экономия ;) )
[quote="WingLion"]При исполнении команд, сначала исполняется самая правая (младшая) четверка бит, сдвиг в регистре команды происходит на 4 бита 'вправо'.[/quote]Просто на рисунке сделано по-другому и может вызвать запинки и ненужные вопросы. Хотя это м.б. и тест на понимание, типа входного контроля читающего, как посмотреть... ;)
[quote="WingLion"][quote="in4"]Может, ввести термин CELL для обозначения адресуемой единицы памяти (и одновременно группы команд в ней)?[/quote]
Ну странновато звучит предложение ввести термин, который уже давно как бы стандартен [/quote]Имелось ввиду использовать этот термин в описании проца. ;)
(Сейчас не используется и ячейки называются длинными фразами "группа команд" (=CELL), "группами, упакованными в машинное слово"(=CELL-ами), "среди загруженных команд"(=в CELL) и т.п.)
Кстати, не хочешь бОльше условий добавить?
Проверку на отрицательное, по переносу (если флаг переноса делать не хочешь, тогда почему?) Как без переноса делать [b]D+[/b] ?
|
|
|
|
Добавлено: Сб дек 05, 2009 11:21 |
|
|
|
|
|
| |
Заголовок сообщения: |
|
|
|
in4 писал(а): Согласен. А еще для эффективности остаток CELL луше заполнять NOP-ами собственно, особого смысла в этом нет, потому что после первого же CALL в процессоре NOP (загрузка группы команд из адреса, куда вызов произошел) выполняется автоматом. А я подумываю о том, чтобы использовать оставшееся пространство для коротких вызовов, например, сделать так, что если за командой CALL следует не нулевой ниббл, то исполняется одна из 15 подпрограмм с фиксированным адресом. Подобно INT #nn в Z80. in4 писал(а): Да. Но если CALL сделать последней командой, то предыдущие команды CELL-а могут еще много чего сделать. Например, загрузить 3 литерала! Wink
А если подряд несколько CALL-ов, то да, один CALL на CELL Да, так и есть. Кстати, слово, вызванное через адресный интерпретатор, вполне может достать адрес со стека возвратов, взять несколько слов, расположенных после своего адреса в потоке интерпретации и вернуть на стек возвратов модифицированный адрес, т.е. параметры для слова могут следовать за его адресом непосредственно. Хм... вот, прямо тут сразу и идейка появилась для новой команды! ) R+@ которая выполняет R> DUP 1+ >R @ для вытаскивания такого операнда (за 2 такта). Думаю, такое слово будет полезно. В процессоре оно будет исполняться очень быстро, и в железе оно не много места потребует, потому что R> DUP 1+>R фактически уже делается для NEXT. in4 писал(а): Будет ли выгода от аппаратной адресной интерпретации? Были ли сделаны оценки эффективности? В форте каждое высокоуровневое слово требует исполнения NEXT, если и само NEXT будет высокоуровневым, то задержка окажется существенной. : NEXT R> DUP 1+ >R EXECUTE ; - грубо - 5 тактов, а в железе NEXT исполняется за 2 такта, Если в каждом высокоуровневом слове в среднем 5-7 слов, то получается 15-25 тактов выигрыша на каждое слово. Мелочь, конечно, но душу греет. Кроме того, железный NEXT позволяет делать очень коротенькие слова вплоть до 1 CELL на слово, т.е. в одном слове три команды + NEXT, а в потоке адресной интерпретации только ссылка на адрес, где это слово с командами лежит. Т.е. хороший выигрыш не только по тактам, но и по занимаемому объему, что довольно важно для ограниченной внутренней памяти ПЛИС. in4 писал(а): Вопрос по рисунку http://winglion.ru/equinox/forth-code.pngТам изображен проц с 12-битовым CELL . этот рисунок сильно упрощен. Надо подразумевать, что в CELL может быть от 3 до 16 четверок в CELL in4 писал(а): Где младшие разряды и в какой последовательности будет идти интерпретация? В примере для 16-разрядного CELL (из текста) старшие разряды были слева, а младшие справа. 'младшие' и 'старшие' ('левые' и 'правые') - это формальные названия. Если микросхему развернуть на 180 градусов (хотел написать Цельсия ) порядок изменится, но суть памяти - нет. Так и тут "как вы слово назовете, так оно и поплывет". В смысле, в железе есть некий условный порядок бит, который совпадает с порядком бит в обычном представлении чисел. При исполнении команд, сначала исполняется самая правая (младшая) четверка бит, сдвиг в регистре команды происходит на 4 бита 'вправо'. Пример в регистр команд загрузилось слово 573F -> исполняется последовательность команд F -> 3 -> 7 -> 5 пример безотносительно к тому, что делается в реальном процессоре. in4 писал(а): Может, ввести термин CELL для обозначения адресуемой единицы памяти (и одновременно группы команд в ней)? Ну  странновато звучит предложение ввести термин, который уже давно как бы стандартен in4 писал(а): адресный
Thx![quote="in4"]Согласен. А еще для эффективности остаток CELL луше заполнять NOP-ами [/quote]
собственно, особого смысла в этом нет, потому что после первого же CALL в процессоре NOP (загрузка группы команд из адреса, куда вызов произошел) выполняется автоматом.
А я подумываю о том, чтобы использовать оставшееся пространство для коротких вызовов, например, сделать так, что если за командой CALL следует не нулевой ниббл, то исполняется одна из 15 подпрограмм с фиксированным адресом. Подобно INT #nn в Z80.
[quote="in4"]Да. Но если CALL сделать последней командой, то предыдущие команды CELL-а могут еще много чего сделать. Например, загрузить 3 литерала! Wink
А если подряд несколько CALL-ов, то да, один CALL на CELL[/quote]
Да, так и есть. Кстати, слово, вызванное через адресный интерпретатор, вполне может достать адрес со стека возвратов, взять несколько слов, расположенных после своего адреса в потоке интерпретации и вернуть на стек возвратов модифицированный адрес, т.е. параметры для слова могут следовать за его адресом непосредственно.
Хм... вот, прямо тут сразу и идейка появилась для новой команды! ;)) [b]R+@[/b] которая выполняет [b]R> DUP 1+ >R @[/b] для вытаскивания такого операнда (за 2 такта).
Думаю, такое слово будет полезно. В процессоре оно будет исполняться очень быстро, и в железе оно не много места потребует, потому что [b]R> DUP 1+>R[/b] фактически уже делается для [b]NEXT[/b].
[quote="in4"]Будет ли выгода от аппаратной адресной интерпретации? Были ли сделаны оценки эффективности? [/quote]
В форте каждое высокоуровневое слово требует исполнения NEXT, если и само NEXT будет высокоуровневым, то задержка окажется существенной.
[b]: NEXT R> DUP 1+ >R EXECUTE ;[/b] - грубо - 5 тактов, а в железе NEXT исполняется за 2 такта,
Если в каждом высокоуровневом слове в среднем 5-7 слов, то получается 15-25 тактов выигрыша на каждое слово. Мелочь, конечно, но душу греет. ;)
Кроме того, железный NEXT позволяет делать очень коротенькие слова вплоть до 1 CELL на слово, т.е. в одном слове три команды + NEXT, а в потоке адресной интерпретации только ссылка на адрес, где это слово с командами лежит. Т.е. хороший выигрыш не только по тактам, но и по занимаемому объему, что довольно важно для ограниченной внутренней памяти ПЛИС.
[quote="in4"]Вопрос по рисунку http://winglion.ru/equinox/forth-code.png
Там изображен проц с 12-битовым CELL . [/quote]
этот рисунок сильно упрощен. Надо подразумевать, что в CELL может быть от 3 до 16 четверок в CELL
[quote="in4"]Где младшие разряды и в какой последовательности будет идти интерпретация? В примере для 16-разрядного CELL (из текста) старшие разряды были слева, а младшие справа. [/quote]
'младшие' и 'старшие' ('левые' и 'правые') - это формальные названия. Если микросхему развернуть на 180 градусов (хотел написать Цельсия ;) ) порядок изменится, но суть памяти - нет.
Так и тут "как вы слово назовете, так оно и поплывет". В смысле, в железе есть некий условный порядок бит, который совпадает с порядком бит в обычном представлении чисел.
При исполнении команд, сначала исполняется самая правая (младшая) четверка бит, сдвиг в регистре команды происходит на 4 бита 'вправо'.
Пример в регистр команд загрузилось слово 573F -> исполняется последовательность команд F -> 3 -> 7 -> 5 пример безотносительно к тому, что делается в реальном процессоре.
[quote="in4"]Может, ввести термин CELL для обозначения адресуемой единицы памяти (и одновременно группы команд в ней)?[/quote]
Ну :shuffle; странновато звучит предложение ввести термин, который уже давно как бы стандартен ;)
[quote="in4"]адресный[/quote]
[b]Thx![/b]
|
|
|
|
Добавлено: Сб дек 05, 2009 08:23 |
|
|
|
|
|
| |
Заголовок сообщения: |
|
|
|
WingLion писал(а): in4 писал(а): для 16-битного варианта процессора, до 8 операндов для 32-хбитного и до 16 операндов для 64битного. Вот тут не понял, в чем вопрос. В описании изначально 3 варианта процессора 16,32 и 64-битные. Цитата: для 16-битного варианта процессора, до 8 операндов для 32-хбитного и до 16 операндов для 64битного. WingLion писал(а): 4 CALL в одной CELL не имеют смысла, так как достаточно одного для вызова адресного интерпретатора. Согласен. А еще для эффективности остаток CELL луше заполнять NOP-ами WingLion писал(а): Если же надо исполнить несколько подпрограмм (заканчивающихся на RET) подряд, тогда каждый CALL займет дополнительный CELL Да. Но если CALL сделать последней командой, то предыдущие команды CELL-а могут еще много чего сделать. Например, загрузить 3 литерала! А если подряд несколько CALL-ов, то да, один CALL на CELL  WingLion писал(а): Разве что небольшое неудобство, что каждую подпрограмму надо в форт-слово оформлять, чтобы использовать ее вызов через адресный интерпретатор. Будет ли выгода от аппаратной адресной интерпретации? Были ли сделаны оценки эффективности? Вопрос по рисунку http://winglion.ru/equinox/forth-code.pngТам изображен проц с 12-битовым CELL . Где младшие разряды и в какой последовательности будет идти интерпретация? В примере для 16-разрядного CELL (из текста) старшие разряды были слева, а младшие справа. Цитата: Команды загружаются в процессор группами, упакованными в машинное слово, и исполняются последовательно от младшей тетрады бит к старшей. Может, ввести термин CELL для обозначения адресуемой единицы памяти (и одновременно группы команд в ней)? Вроде через это будет проще изложить... Цитата: слово MyWORD оформленное для исполнения через адрсный адресный [quote="WingLion"][quote="in4"]для 16-битного варианта процессора, до 8 операндов для 32-хбитного и до 16 операндов для 64битного.[/quote]
Вот тут не понял, в чем вопрос. В описании изначально 3 варианта процессора 16,32 и 64-битные.[/quote]
[quote]для 1[b]6-б[/b]итного варианта процессора, до 8 операндов для 3[b]2-хб[/b]итного и до 16 операндов для 6[b]4б[/b]итного.[/quote]
[quote="WingLion"]4 CALL в одной CELL не имеют смысла, так как достаточно одного для вызова адресного интерпретатора.[/quote]Согласен. А еще для эффективности остаток CELL луше заполнять NOP-ами
[quote="WingLion"]Если же надо исполнить несколько подпрограмм (заканчивающихся на RET) подряд, тогда каждый CALL займет дополнительный CELL[/quote]Да. Но если CALL сделать последней командой, то предыдущие команды CELL-а могут еще много чего сделать. Например, загрузить 3 литерала! ;)
А если подряд несколько CALL-ов, то да, один CALL на CELL :(
[quote="WingLion"]Разве что небольшое неудобство, что каждую подпрограмму надо в форт-слово оформлять, чтобы использовать ее вызов через адресный интерпретатор.[/quote]Будет ли выгода от аппаратной адресной интерпретации? Были ли сделаны оценки эффективности?
Вопрос по рисунку http://winglion.ru/equinox/forth-code.png
Там изображен проц с 12-битовым CELL .
Где младшие разряды и в какой последовательности будет идти интерпретация? В примере для 16-разрядного CELL (из текста) старшие разряды были слева, а младшие справа.
[quote]Команды загружаются в процессор группами, упакованными в машинное слово, и исполняются последовательно [b]от младшей[/b] тетрады бит [b]к старшей[/b].[/quote]
Может, ввести термин CELL для обозначения адресуемой единицы памяти (и одновременно группы команд в ней)? Вроде через это будет проще изложить...
[quote]слово MyWORD оформленное для исполнения через адрсный[/quote]адресный
|
|
|
|
Добавлено: Сб дек 05, 2009 02:37 |
|
|
|
|
|
| |
Заголовок сообщения: |
|
|
|
in4 писал(а): Можно ли сделать чтение следующего адреса не через фиктивную команду, а от счетчика нибблов? Мне почему-то кажется что так будет проще, но если есть серьезные возражения, объясните, пожалуйста!
Из всех вариантов, какие я перебирал при разработке форт-процессоров с малой битностью команды этот наиболее простой. Счетчик нибблов только мешает и усложняет дешифрацию, а вместе с этим уменьшает общую скорость работы процессора. [quote="in4"]Можно ли сделать чтение следующего адреса не через фиктивную команду, а от счетчика нибблов? Мне почему-то кажется что так будет проще, но если есть серьезные возражения, объясните, пожалуйста![/quote]
Из всех вариантов, какие я перебирал при разработке форт-процессоров с малой битностью команды этот наиболее простой. Счетчик нибблов только мешает и усложняет дешифрацию, а вместе с этим уменьшает общую скорость работы процессора.
|
|
|
|
Добавлено: Пт дек 04, 2009 21:57 |
|
|
|
|
|
| |
Заголовок сообщения: |
|
|
|
in4, спасибо за вычитку!
in4 писал(а): для 16-битного варианта процессора, до 8 операндов для 32-хбитного и до 16 операндов для 64битного. Вот тут не понял, в чем вопрос. В описании изначально 3 варианта процессора 16,32 и 64-битные. in4 писал(а): Переходить ведь можно только на границы CELL (группы из нескольких команд в соответствии с разрядностью процессора, для E16 - размер CELL 16 бит)? да. Промежуточные адреса для процессора формально и не существуют. in4 писал(а): Так в одной CELL может ли быть 4 CALL подряд? Куда тогда будет RET? 4 CALL в одной CELL не имеют смысла, так как достаточно одного для вызова адресного интерпретатора. Если же надо исполнить несколько подпрограмм (заканчивающихся на RET) подряд, тогда каждый CALL займет дополнительный CELL in4 писал(а): На картинке также есть NEXT-RET, что это? адрес перехода на код с двумя командами: RDROP и NEXT - на рисунке это видно. in4 писал(а): И, после некоторых раздумий, рисунок показался обычным адресным интерпретатором прямого ШК, как из Ноздрунова... фактически так и есть. Прямой шитый код с реализацией адресного интерпретатора не в программе, а в железе. in4 писал(а): Только тогда текст вокруг не совсем понятен.. Надо бы понять, что именно непонятно... in4 писал(а): Использование NEXT предполагает знание в подпрограмме того, что за ее вызовом обязательно следует адрес следующей подпрограммы, а это серьезное ограничение использования подпрограмм!
Ведь при обычном программировании за адресом продпрограммы может быть код, готовящий параметры для вызова следующей подпрограммы! Ограничений особо и не видно. Разве что небольшое неудобство, что каждую подпрограмму надо в форт-слово оформлять, чтобы использовать ее вызов через адресный интерпретатор. in4 писал(а): Ведь при обычном программировании за адресом продпрограммы может быть код, готовящий параметры для вызова следующей подпрограммы!
туда возврат происходит по RET. Если именно это и надо в конкретном месте, надо вызывать подпрограмму, заканчивающуюся на RET.
Если же в конкретном месте надо ее использовать в потоке адресной интерпретации, то вызывать надо не саму подпрограмму, а ее клон (с оберткой из CALL и NEXT)
п.с. Описание поправил как сумел.
[b]in4[/b], спасибо за вычитку!
[quote="in4"]для 16-битного варианта процессора, до 8 операндов для 32-хбитного и до 16 операндов для 64битного.[/quote]
Вот тут не понял, в чем вопрос. В описании изначально 3 варианта процессора 16,32 и 64-битные.
[quote="in4"]Переходить ведь можно только на границы CELL (группы из нескольких команд в соответствии с разрядностью процессора, для E16 - размер CELL 16 бит)?[/quote]
да. Промежуточные адреса для процессора формально и не существуют.
[quote="in4"]Так в одной CELL может ли быть 4 CALL подряд? Куда тогда будет RET? [/quote]
4 CALL в одной CELL не имеют смысла, так как достаточно одного для вызова адресного интерпретатора.
Если же надо исполнить несколько подпрограмм (заканчивающихся на RET) подряд, тогда каждый CALL займет дополнительный CELL
[quote="in4"]На картинке также есть NEXT-RET, что это? [/quote]
адрес перехода на код с двумя командами: RDROP и NEXT - на рисунке это видно.
[quote="in4"]И, после некоторых раздумий, рисунок показался обычным адресным интерпретатором прямого ШК, как из Ноздрунова...[/quote]
фактически так и есть. Прямой шитый код с реализацией адресного интерпретатора не в программе, а в железе.
[quote="in4"]Только тогда текст вокруг не совсем понятен..[/quote]
Надо бы понять, что именно непонятно...
[quote="in4"]Использование NEXT предполагает знание в подпрограмме того, что за ее вызовом обязательно следует адрес следующей подпрограммы, а это серьезное ограничение использования подпрограмм!
Ведь при обычном программировании за адресом продпрограммы может быть код, готовящий параметры для вызова следующей подпрограммы![/quote]
Ограничений особо и не видно. Разве что небольшое неудобство, что каждую подпрограмму надо в форт-слово оформлять, чтобы использовать ее вызов через адресный интерпретатор.
[quote="in4"]Ведь при обычном программировании за адресом продпрограммы может быть код, готовящий параметры для вызова следующей подпрограммы![/quote]
туда возврат происходит по RET. Если именно это и надо в конкретном месте, надо вызывать подпрограмму, заканчивающуюся на RET.
Если же в конкретном месте надо ее использовать в потоке адресной интерпретации, то вызывать надо не саму подпрограмму, а ее клон (с оберткой из CALL и NEXT)
п.с. Описание поправил как сумел.
|
|
|
|
Добавлено: Пт дек 04, 2009 21:55 |
|
|
|
|
|
| |
Заголовок сообщения: |
|
|
|
|
И про NOP
Можно ли сделать чтение следующего адреса не через фиктивную команду, а от счетчика нибблов? Мне почему-то кажется что так будет проще, но если есть серьезные возражения, объясните, пожалуйста!
И про NOP
Можно ли сделать чтение следующего адреса не через фиктивную команду, а от счетчика нибблов? Мне почему-то кажется что так будет проще, но если есть серьезные возражения, объясните, пожалуйста!
|
|
|
|
Добавлено: Пт дек 04, 2009 06:01 |
|
|
|
|
|
| |
Заголовок сообщения: |
|
|
|
Извиняюсь за некоторый сумбур. Текст письма редактировался несколько раз параллельно с разглядыванием рисунка...
К чему стал смотреть - появилась нужда в витруальном проце. А тут Форум напомнил про E16...
Теперь вопросы.
Переходить ведь можно только на границы CELL (группы из нескольких команд в соответствии с разрядностью процессора, для E16 - размер CELL 16 бит)?
Цитата: Объем кода уменьшается за счет отсутствия кодов команды CALL перед каждым адресом в последовательности вызовов. Так в одной CELL может ли быть 4 CALL подряд? Куда тогда будет RET?
Пока похоже только на границу CELL? Значит, в одной CELL может быть только последняя(в смысле исполнения команд из CELL) CALL? И если она в начале, остальной код из CELL выполняется или нет? Скорее нет, но если выполняется, то когда?
На картинке также есть NEXT-RET, что это?
И, после некоторых раздумий, рисунок показался обычным адресным интерпретатором прямого ШК, как из Ноздрунова... И приведенная цитата как раз про него... Только тогда текст вокруг не совсем понятен...  Точно переработать не надо?
Да, предложенная техника использования NEXT вызывает вопросы. Использование NEXT предполагает знание в подпрограмме того, что за ее вызовом обязательно следует адрес следующей подпрограммы, а это серьезное ограничение использования подпрограмм!
Ведь при обычном программировании за адресом продпрограммы может быть код, готовящий параметры для вызова следующей подпрограммы! Извиняюсь за некоторый сумбур. Текст письма редактировался несколько раз параллельно с разглядыванием рисунка... ;)
К чему стал смотреть - появилась нужда в витруальном проце. А тут Форум напомнил про E16... ;)
Теперь вопросы.
Переходить ведь можно только на границы CELL (группы из нескольких команд в соответствии с разрядностью процессора, для E16 - размер CELL 16 бит)?
[quote]Объем кода уменьшается за счет отсутствия кодов команды CALL перед каждым адресом в последовательности вызовов.[/quote]Так в одной CELL может ли быть 4 CALL подряд? Куда тогда будет RET?
Пока похоже только на границу CELL? Значит, в одной CELL может быть только последняя(в смысле исполнения команд из CELL) CALL? И если она в начале, остальной код из CELL выполняется или нет? Скорее нет, но если выполняется, то когда?
На картинке также есть NEXT-RET, что это?
И, после некоторых раздумий, рисунок показался обычным адресным интерпретатором прямого ШК, как из Ноздрунова... ;) И приведенная цитата как раз про него... ;) Только тогда текст вокруг не совсем понятен... :roll: Точно переработать не надо? ;)
Да, предложенная техника использования NEXT вызывает вопросы. Использование NEXT предполагает знание [b]в подпрограмме[/b] того, что за ее вызовом [b]обязательно[/b] следует [b]адрес[/b] следующей подпрограммы, а это серьезное ограничение использования подпрограмм!
Ведь при обычном программировании за адресом продпрограммы может быть [b]код[/b], готовящий параметры для вызова следующей подпрограммы!
|
|
|
|
Добавлено: Пт дек 04, 2009 05:37 |
|
|
|
|
|
| |
Заголовок сообщения: |
|
|
|
Внимательно вычитываю описание E16 Эти места мне не очень понравились...
Цитата: и исполняются последовательно от младшей тетрады бит к старшей Добавить точку в конце предложения Цитата: для 16-битного варианта процессора, до 8 операндов для 32-хбитного и до 16 операндов для 64битного. 3 разных описания х-битного Цитата: таким образом в младших битах регистра сдвига каждый такт оказывается какая-либо команда м. "на каждом такте"? Но спорить сильно не буду... просто чтение запнулось и захотелось как-то попроще... Цитата: команд и, таким образом обеспечивает непрерывное поступление команд или убрать запятую, или поставить еще, выделив "таким образом" Цитата: Префиксные команды состоят из двух четверок Команды с префиксами - "префиксные" м. иметь и др. значения ; четверок бит Цитата: Исполнение префиксных команд команд с префиксами - "префиксные" м. иметь и др. значения Цитата: исполняется команда следующая за префиксом команда, следующая Цитата: командой CALL. вслед за которой точку на запятую Цитата: Каждая программа, исполняемое адресным интерпретатором исполняемая (заметил, а потом стал искать сначала и получилось, стал вычитывать... ) Внимательно вычитываю описание E16 ;) Эти места мне не очень понравились... :(
[quote]и исполняются последовательно от младшей тетрады бит к старшей[/quote]Добавить точку в конце предложения
[quote]для 16-битного варианта процессора, до 8 операндов для 32-хбитного и до 16 операндов для 64битного.[/quote]3 разных описания х-битного ;)
[quote]таким образом в младших битах регистра сдвига [b]каждый такт[/b] оказывается какая-либо команда[/quote]м. "на каждом такте"? Но спорить сильно не буду... ;) просто чтение запнулось и захотелось как-то попроще... ;)
[quote]команд и, таким образом обеспечивает непрерывное поступление команд[/quote]или убрать запятую, или поставить еще, выделив "таким образом"
[quote]Префиксные команды состоят из двух четверок[/quote]Команды с префиксами - "префиксные" м. иметь и др. значения :( ; четверок бит
[quote]Исполнение префиксных команд[/quote]команд с префиксами - "префиксные" м. иметь и др. значения :(
[quote]исполняется команда следующая за префиксом[/quote]команда, следующая
[quote]командой CALL. вслед за которой[/quote]точку на запятую
[quote]Каждая программа, исполняем[b]ое[/b] адресным интерпретатором[/quote]исполняемая (заметил, а потом стал искать сначала и получилось, стал вычитывать... ;) )
|
|
|
|
Добавлено: Пт дек 04, 2009 04:26 |
|
|
|
|
|
| |
Заголовок сообщения: |
|
|
|
вопрос писал(а): Я хочу уточнить - NEXT в данном случае соответтствует (для Интел) jmp или точнее "jmp исполняемое параллельно" ?
NEXT соответствует параллельному исполнению двух команд RET и тут же CALL без чтения кода команды из адреса, куда вернулись.
Этот механизм пояснен здесь: http://winglion.ru/equinox/#3[quote="вопрос"]Я хочу уточнить - NEXT в данном случае соответтствует (для Интел) jmp или точнее "jmp исполняемое параллельно" ? [/quote]
NEXT соответствует параллельному исполнению двух команд RET и тут же CALL без чтения кода команды из адреса, куда вернулись.
Этот механизм пояснен здесь: http://winglion.ru/equinox/#3
|
|
|
|
Добавлено: Пт дек 04, 2009 01:04 |
|
|
|
|
{kind=link}